

Expressvpn Glossary
Data poisoning

What is data poisoning?
Data poisoning is a type of attack in which malicious actors manipulate, corrupt, or insert data into a dataset to influence how a system learns from or uses that data.
Machine learning (ML) projects are often targeted by data poisoning attacks, but the tactic can also affect search results, user reviews, analytics, and more. That said, this entry focuses on data poisoning in the context of AI.
The goal of a data poisoning attack is to manipulate how a system interprets data or responds to certain inputs.
How does data poisoning work?
Data poisoning can occur at any stage of data collection, labeling, curation, or addition to a model’s training or fine-tuning pipeline. To poison such data, an attacker typically:
- Injects malicious samples: Attackers add misleading or manipulated data into the training dataset.
- Alters labels or features: Existing samples are modified to influence how the model ultimately functions.
- Influences model behavior: The poisoned data is designed to alter the model's response to specific inputs.
Once trained on poisoned data, the AI may behave differently than its creators intended. The changes can be broad, such as reducing overall accuracy, or limited to specific inputs, subjects, or triggers.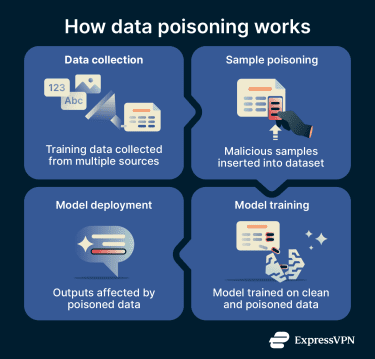
Types of data poisoning
Different attack strategies may be used to achieve different goals. These approaches differ in how they poison the training data and can have distinct impacts on the model's behavior.
Several types of data poisoning are recognized in ML research, including:
- Label poisoning: Correct samples are given incorrect labels to influence the model into making incorrect associations.
- Backdoor poisoning: Hidden triggers cause the model to behave incorrectly when specific inputs appear.
- Availability poisoning: Large amounts of corrupted data degrade the model's overall performance.
- Targeted poisoning: Training data is manipulated so the model makes predictable errors for specific inputs, classes, or scenarios.
- Clean-label poisoning: Samples appear legitimate yet still influence the model's behavior.
These categories can overlap; for example, a clean-label attack may also be targeted or used to introduce a backdoor. Some attacks aim to reduce accuracy across the entire system, while others create narrowly targeted weaknesses that remain hidden until triggered.
Why is data poisoning important?
Data poisoning can undermine trust in AI systems by weakening the reliability of the data used to train or fine-tune them.
When corrupted samples influence an ML model during training, the system may produce inaccurate predictions, develop hidden vulnerabilities, or respond incorrectly to specific triggers. These weaknesses may remain unnoticed during testing or early deployment.
For example, in an autonomous-vehicle training dataset, attackers could add or alter traffic-sign images so that stop signs are incorrectly labeled as speed-limit signs. If the poisoned data influences the model, it may misclassify real-world traffic signs, creating a safety risk.
Additionally, security systems trained on corrupted data may fail to detect real threats. AI tools affected by data poisoning can also create reputational, security, and compliance concerns for developers, especially if the issue points to weak data governance or insufficient dataset validation.
Where is it used?
Data poisoning can affect ML systems that depend on large, externally sourced, or frequently updated datasets.
Large language model (LLM) chatbots are a high-profile target because of their popularity and potential influence. Training or retrieval data may be poisoned to bias how a model presents politics, current events, scientific debates, or history. In this way, data poisoning could be used for misinformation, influence, or propaganda.
Other common targets include:
- Email spam filtering systems: Models trained to classify incoming messages as spam or legitimate.
- Fraud detection platforms: Systems that learn patterns in financial transactions and user behavior.
- Content moderation tools: AI models used to identify harmful or prohibited online content.
- Recommendation engines: Algorithms that suggest products, videos, or posts based on user activity.
- Autonomous technologies: Systems, such as self-driving vehicles and robotics, that rely on trained perception models.
Not every misleading data point is a formal data poisoning attack. For example, an individual may provide false information, click on ads that don’t interest them, or view content outside their usual preferences. These actions can make profiling or recommendation systems less accurate for that person, but they are usually better described as signal obfuscation or data pollution unless they are intended to manipulate a model or dataset at scale.
Further reading
- What is a prompt injection attack, and how can it be prevented?
- How to stop AI from stealing your art
- What is security posture? A complete guide for organizations
- DeepSeek vs. ChatGPT: Which AI tool protects your data better?


